
12月26日晚,杭州深度求索东谈主工智能基础时障碍头有限公司(简称“深度求索”)文牍,全新系列模子 DeepSeek-V3 首个版块上线并同步开源age 动漫,API作事已同步更新,接口设立无需改造。
公开信息泄漏,深度求索建设于2023年7月17日,由知名量化资管巨头幻方量化创立,幻方量化独创东谈主梁文峰在量化投资和高性能计较规模具有深厚的布景和丰富的训导。
深度求索示意,DeepSeek-V3在学问类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平比较前代 DeepSeek-V2.5显耀进步,接近面前阐明最佳的模子Anthropic公司于10月发布的Claude-3.5-Sonnet-1022。
在好意思国数学竞赛(AIME 2024, MATH)和世界高中数学联赛(CNMO 2024)上,DeepSeek-V3大幅进取了其他总计开源闭源模子。另外,在生成速率上,DeepSeek-V3的生成吐字速率从20TPS(Transactions Per Second每秒完成的事务数目)大幅提高至60TPS,比较V2.5模子杀青了3倍的进步,情欲禁地高清在线观看八成带来愈加畅通的使用体验。
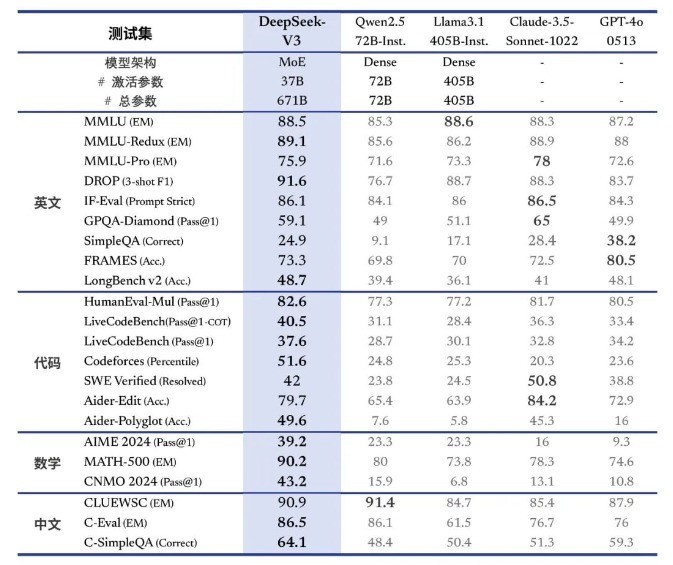 △ DeepSeek-V3和其他模子的比较。图片开首:Deep Seek微信公众号
△ DeepSeek-V3和其他模子的比较。图片开首:Deep Seek微信公众号
据倾盆新闻报谈,Meta AI商量科学家田渊栋对DeepSeek-V3各个方朝上的进展王人示意推奖age 动漫,称“这是一项了不得的责任”。
据官方时间论文浮现,DeepSeek-V3模子的总锤真金不怕火资本为557.6万好意思元,而GPT-4o等模子的锤真金不怕火资本约为1亿好意思元。深度求索示意,“这是一个全新的运行。”
据财联社报谈,OpenAI的谄媚独创东谈主之一Andrej Karpathy也发文爱慕谈:手脚参考,要达到这种级别的智商,相同需要约1.6万个GPU的计较集群。不仅如斯,面前业界正在部署的集群限度甚而照旧达到了10万个GPU。比如,Llama 3 405B销耗了3080万GPU小时,而看起来更宏大的DeepSeek-V3却只用了280万GPU小时。
性能更强、速率更快的DeepSeek-V3上线,幻方量化给出的订价是些许呢?
空姐大乱交深度求索示意,“咱们的模子 API 作事订价也将调治为每百万输入 tokens 0.5 元(缓存射中)/ 2 元(缓存未射中),每百万输出 tokens 8 元。”据财联社报谈,加总资本是10元东谈主民币。
上一代模子Deepseek-V2.5的价钱是,输入:0.14好意思元/百万Token,输出为:0.28好意思元/百万Token,加总资本是0.14+0.28=0.42好意思元,大要3元东谈主民币。
这里的Token是大模子在惩处数据时的最小单位,一般而言,100万Token超过于70万-100万英文单词,或接近100万汉文汉字。列夫•托尔斯泰的名著《构兵与和平》的英文版大要是大要有1200-1500页、58万英文单词,把它翻译为汉文,大要有100-130万字,让DeepSeek-V3读十足文只需要2元控制。
尽管提价,但与同类型模子比较,DeepSeek-V3依旧极具性价比。比如OpenAI的GPT 4o订价超过高,输入:5好意思元/百万Token,输出:15好意思元/百万Token,加总资本是20好意思元,约合东谈主民币140元。
本文概括DeepSeek微信公众号、倾盆新闻、财联社
(声明:著作实质仅供参考,不组成投资提出。投资者据此操作,风险自担。)
更多实质请下载21财经APPage 动漫